在Java中,Object类是所有类的父类,任何类都默认继承Object。
一、Object的中的公有方法
1.8中的源码
1 | package java.lang; |
1、getClass()方法
final方法,说明子类中不可重写。
获得运行时类型。
2、hashCode()方法
该方法用于哈希查找,可以减少在查找中使用equals的次数,重写了equals方法一般都要重写hashCode方法。这个方法在一些具有哈希功能的Collection中用到。
Effective Java中提到:
在每个覆盖了equals方法的类中,也必须覆盖hashCode方法。给不同的对象产生不同的hashCode,有助于提高散列表的性能。
至于如何才能为不同的对象产生不同的散列码,先看一下String类中的hashCode方法
1 | public int hashCode() { |
计算方法为:s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1]。
这个书中给出的计算散列码的建议很相似,都是把关键的域乘31再相加。至于为什么是31,书中给出的解释如下:
因为它是一个奇素数。如果乘的是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算。使用素数的好处并不明显,但是习惯上都使用素数来计算散列结果。31有个很好的特性,即用移位和减法来替代乘法,可以得到更好的性能:
31 * i == (i << 5) - i。现代的JVM可以自动完成这种优化。
3、equals方法
该方法是非常重要的一个方法。一般equals和==是不一样的,但是在Object中两者是一样的。子类一般都要重写这个方法。
4、clone()方法
保护方法,实现对象的浅克隆,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。
主要是JAVA里除了8种基本类型传参数是值传递,其他的类对象传参数都是引用传递,我们有时候不希望在方法里讲参数改变,这是就需要在类中复写clone方法。
这里涉及到深克隆与浅克隆的问题。
5、toString()方法
默认返回的是改对象的类名+@+内存地址,一般都会在子类中重写
6、 notify()与notifyAll()方法
notify方法唤醒在该对象上等待的某个线程。
notifyAll方法唤醒在该对象上等待的所有线程。
两个方法都是final的,子类不可以重写
7、wait方法
wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
- 其他线程调用了该对象的notify方法。
- 其他线程调用了该对象的notifyAll方法。
- 其他线程调用了interrupt中断该线程。
- 时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。
也是final的,不可重写
8、finalize()方法
当垃圾回收时用于释放资源,不建议使用
二、wait与notify方法
关于这两个方法在生产着消费者模型和三个线程循环打印abc的文章中已经介绍了,前几天在腾讯面试的时候被问到一个线程执行notify之后后面的代码还会运行吗? 当时没有答上来,回来实际运行了一下,在循环打印ABC的代码后面加了一句话:
1 | public void run(){ |
输出结果:
1 | A |
可以看出后面的代码不但会运行,而且肯定在另一个线程运行直线被执行。
这里涉及到线程的几个状态,在一个线程wait之后,应该是处于阻塞状态。
而一个调用notify的线程肯定是处于运行状态的现在正在持有这个锁,他执行notify之后其实并不会让出线程,因为加锁的代码段还没有执行完毕,notify只是将一个等待队列中的线程唤醒,也就是说使这个线程从阻塞状态变为就绪状态,而不是运行状态。
只有代码段的所有代码执行完毕,包括notify下面的代码,该线程才会让出锁,使得过程那个被唤醒的线程去持有锁。
三、深克隆与浅克隆
Object类里定义了clone方法,关于对象的克隆,分为深克隆与浅克隆。
一个对象要被克隆,有两个前提:
- 实现Cloneable接口,如果没有,会抛出CloneNotSupportedException异常
- 重写Object类中的clone()方法
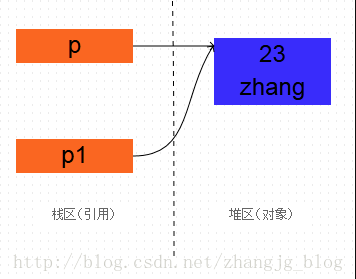
1、复制对象与复制引用
1 | Person p = new Person(23, "zhang"); |
从打印对象可以看出,p和p1的内存地址是相同的,也就是说他们只想相同的对象。
1 | Person p = new Person(23, "zhang"); |
这样才是真正的克隆了一下对象
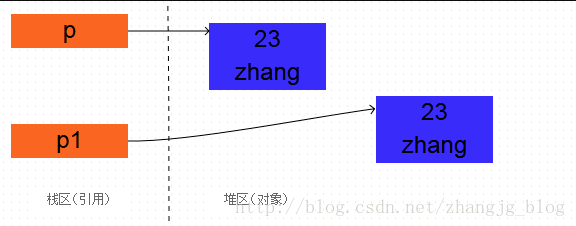
2、深克隆与浅克隆
上面的代码中,Person类只有两个成员变量,分别是int型和String类型。
1 | public class Person implements Cloneable{ |
age是基本数据类型,所以对它的拷贝很简单,直接将值复制过来就可以。
但是name就不一样了,String是一个对象,对它的克隆就有两种
- 直接将源对象中的name的引用值拷贝给新对象的name字段
- 根据原Person对象中的name指向的字符串对象创建一个新的相同的字符串对象,将这个新字符串对象的引用赋给新拷贝的Person对象的name字段
这两种方法分别被称为浅克隆与深克隆

在Object类中的clone方法默认实现的是浅克隆
3、重写clone方法实现深克隆
现在为了要在clone对象时进行深拷贝, 那么就要Clonable接口,覆盖并实现clone方法,除了调用父类中的clone方法得到新的对象, 还要将该类中的引用变量也clone出来。如果只是用Object中默认的clone方法,是浅拷贝的
但是有一个问题:
如果想要深拷贝一个对象, 这个对象必须要实现Cloneable接口,实现clone方法,并且在clone方法内部,把该对象引用的其他对象也要clone一份 , 这就要求这个被引用的对象必须也要实现Cloneable接口并且实现clone方法。
所以完全的深拷贝几乎是不可能的